Interface
Agent-environment loop
The engine exposes state and legal actions; the harness converts them into model-readable context; the model returns a structured action request; and the engine validates and executes it.
Benchmark for LLM Agents
1 Zhejiang University 2 FinVolution Group
PTCG-Bench evaluates language-model agents in a full trading card game setting where agents must reason about hidden information, long-horizon strategy, textual card effects, numerical state, and experience-driven self-improvement.
Leaderboard
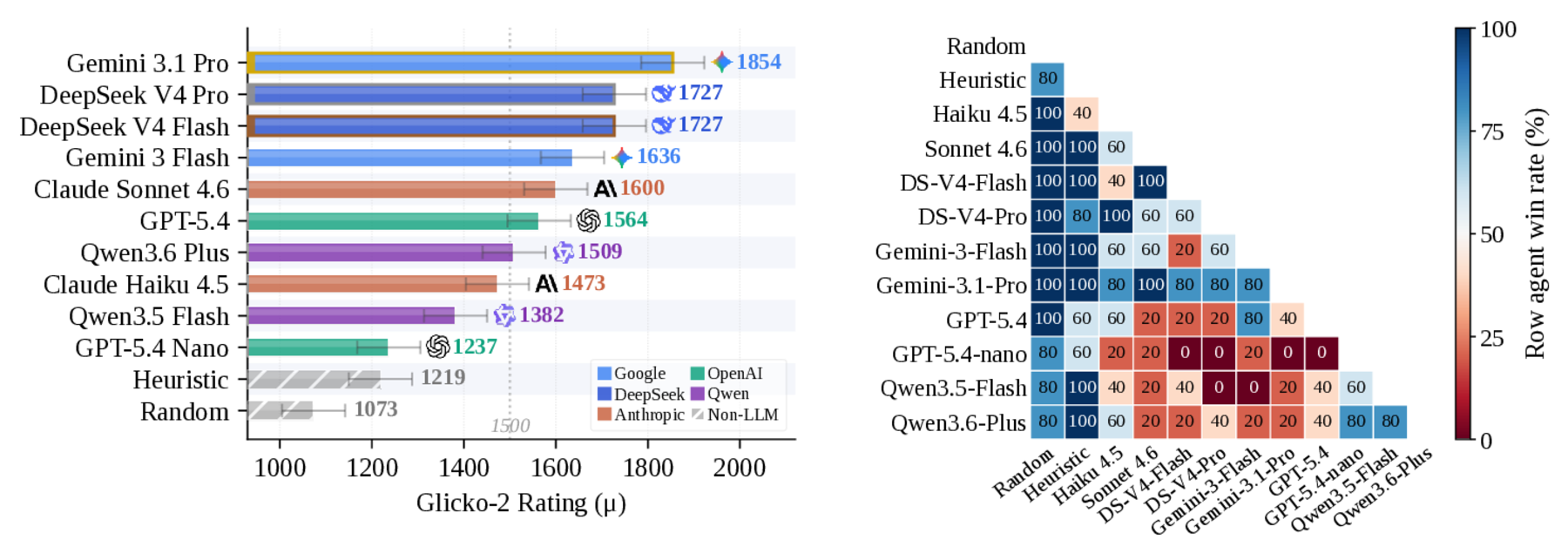
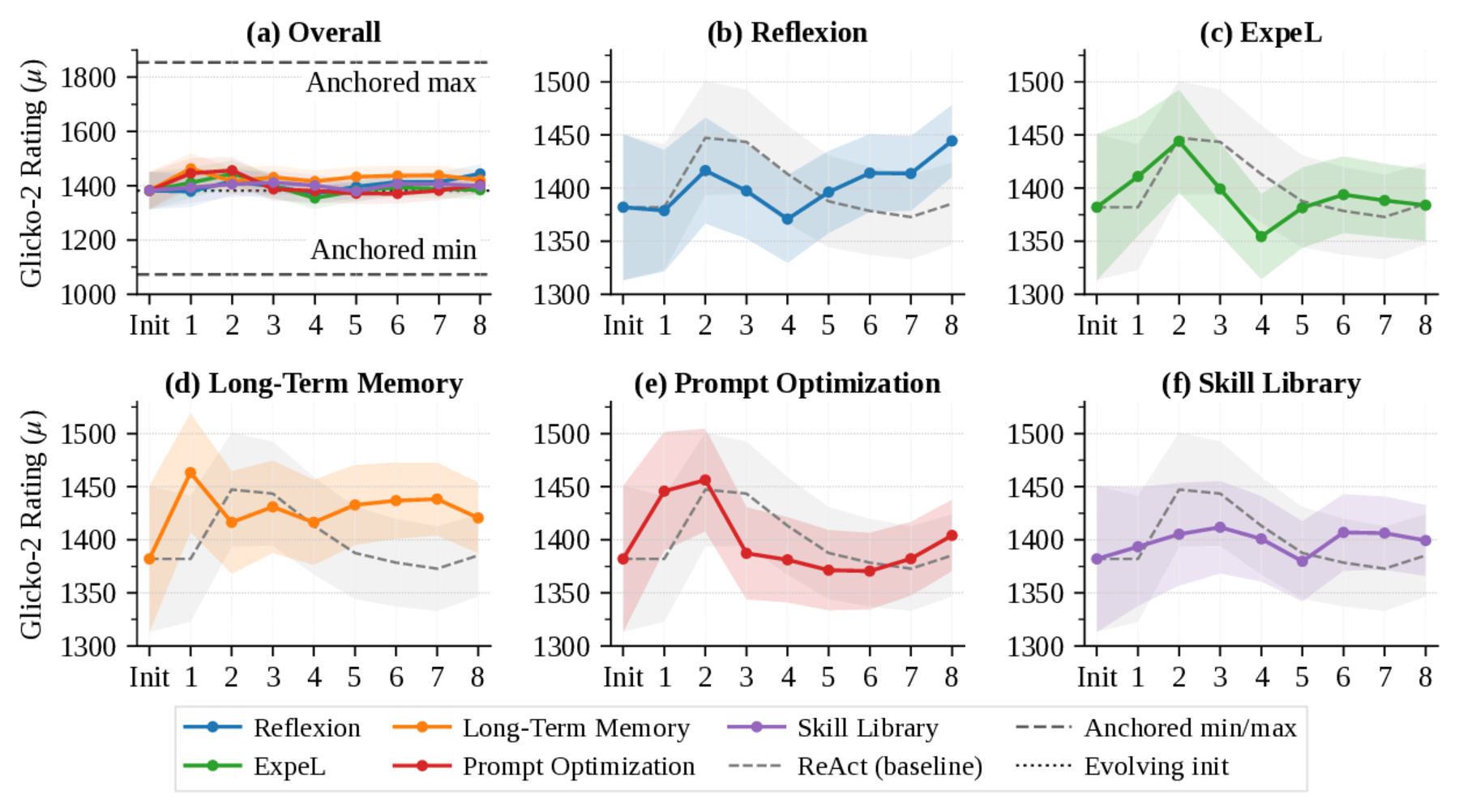
Ratings are shown on the anchored Glicko-2 scale with win/loss records from the referenced benchmark run.
| Rank | Agent | Family | Rating | Deviation | Record | Win Rate | AVG. Cost |
|---|---|---|---|---|---|---|---|
| #1 | Gemini 3.1 Pro Preview | 1854 | ±69 | 47-8 | 85% | $1.15 | |
| #2 | DeepSeek V4 Pro | DeepSeek | 1727 | ±69 | 40-15 | 73% | $0.23 |
| #3 | DeepSeek V4 Flash | DeepSeek | 1727 | ±69 | 40-15 | 73% | $0.09 |
| #4 | Gemini 3 Flash Preview | 1636 | ±69 | 35-20 | 64% | $0.25 | |
| #5 | Claude Sonnet 4.6 | Anthropic | 1600 | ±69 | 33-22 | 60% | $1.94 |
| #6 | GPT-5.4 | OpenAI | 1564 | ±69 | 31-24 | 56% | $0.68 |
| #7 | Qwen 3.6 Plus | Qwen | 1509 | ±69 | 28-27 | 51% | $0.17 |
| #8 | Claude Haiku 4.5 | Anthropic | 1473 | ±69 | 26-29 | 47% | $0.90 |
| #9 | Qwen 3.5 Flash 02-23 | Qwen | 1382 | ±69 | 21-34 | 38% | $0.05 |
| #10 | GPT-5.4 Nano | OpenAI | 1237 | ±69 | 13-42 | 24% | $0.04 |
| #11 | Charizard Heuristic | Heuristic | 1219 | ±69 | 12-43 | 22% | N/A |
| #12 | Random | Baseline | 1073 | ±69 | 4-51 | 7% | N/A |
Overview
A Pokémon Trading Card Game benchmark for evaluating LLM agents in strategic, imperfect-information play.
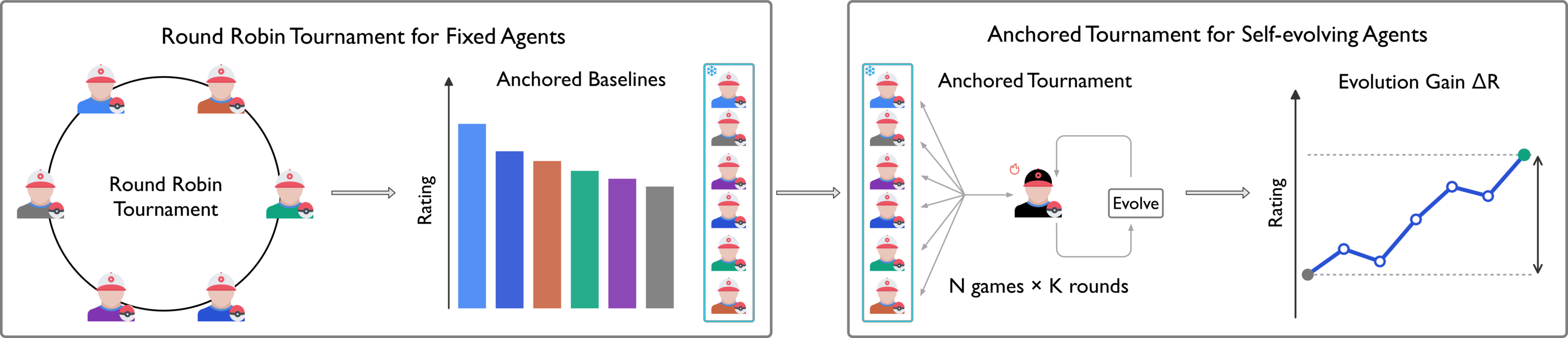
A longitudinal protocol for measuring whether agents improve through accumulated cross-game experience.
A modular harness design that separates backbone capability from observation, action, and context-management choices.
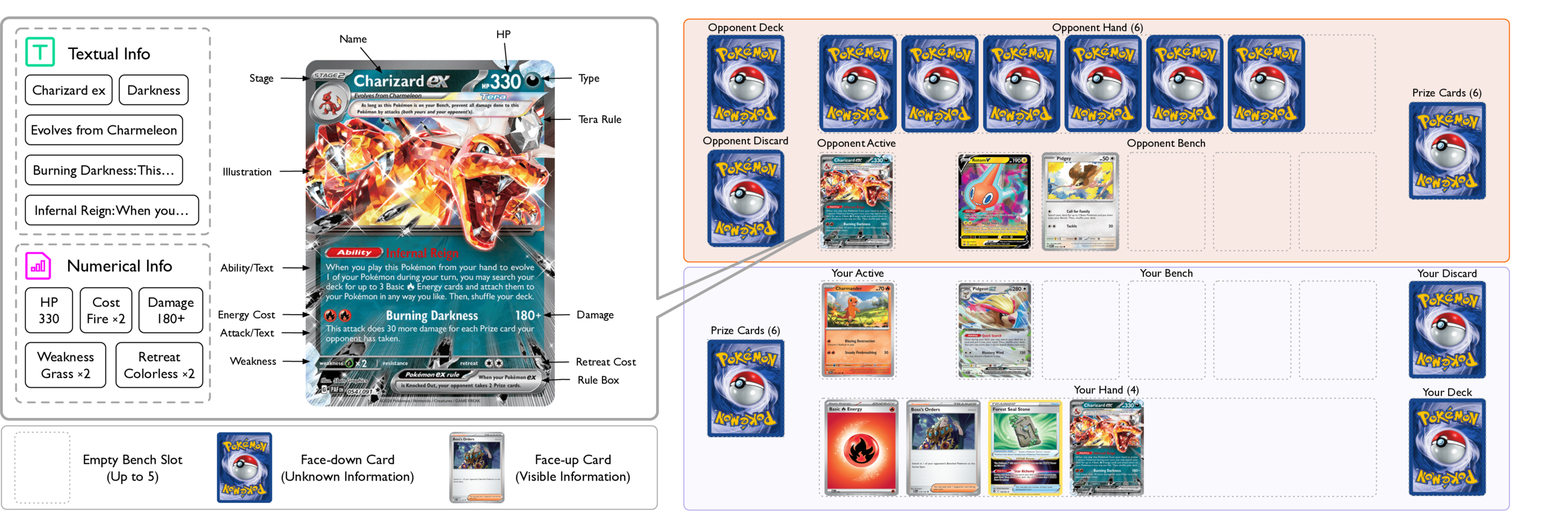
Interface
The engine exposes state and legal actions; the harness converts them into model-readable context; the model returns a structured action request; and the engine validates and executes it.
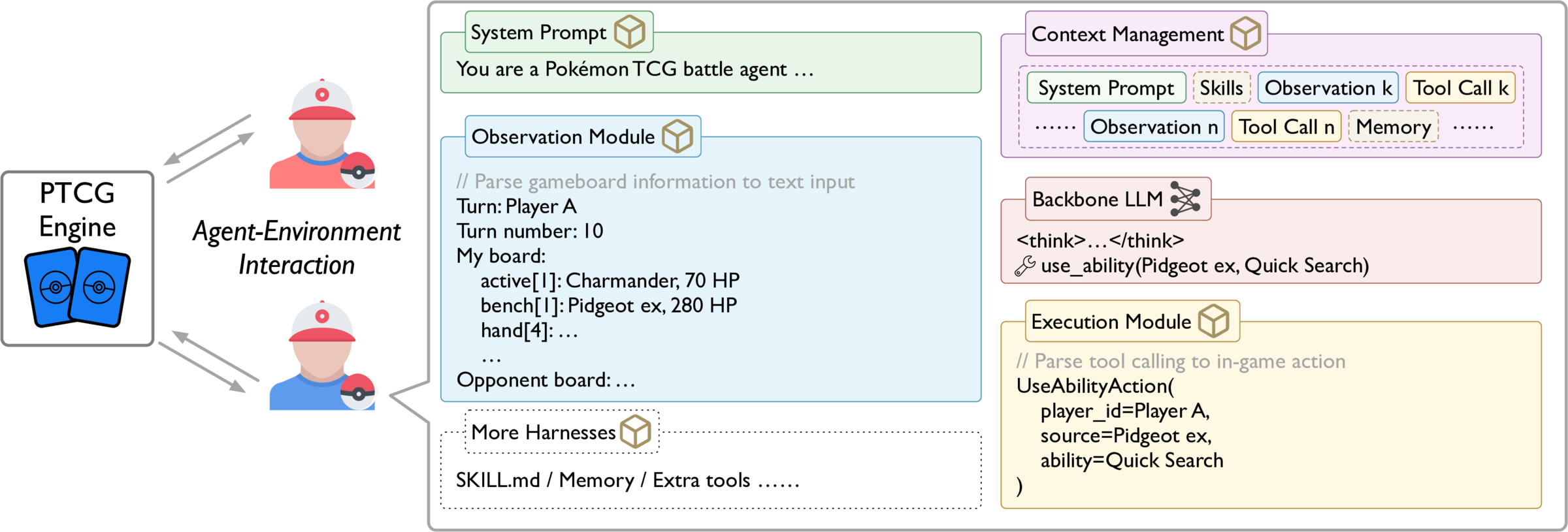
Protocol
Self-evolving agents play repeated games against fixed anchors, update persistent state between rounds, and are evaluated on a stable rating scale across snapshots.
Findings
Experiments show a broad rating distribution across LLM agents, non-monotonic cost-performance trade-offs, and substantial performance changes from harness ablations such as legal-action masking and history context.
The anchored self-evolution study shows that current memory, reflection, prompt-evolution, and skill-library mechanisms do not yet produce stable monotonic improvement across sequential play, highlighting the difficulty of converting long-horizon game experience into reusable strategy.
Citation
@misc{hua2026ptcgbenchllmagentsmaster,
title={PTCG-Bench: Can LLM Agents Master Pok\'emon Trading Card Game?},
author={Dongdong Hua and Yifei Sun and Renhong Huang and Feng Gao and Chunping Wang and Yang Yang},
year={2026},
eprint={2605.29653},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2605.29653},
}